Tinder — Fully explained System Design and Architecture

In this article, I am going to explain about the interesting topic you all want to know. That is Tinder System Design and Architecture. Tinder is an online dating and geosocial networking application launched in 2012 and it has become a very useful and very big application.
Technical Background about Tinder
Tinder doesn't have its database and it is hosted in AWS Cloud. It has a mobile application for Android and iOS. Tinder doesn’t have its database it is hosted in AWS. They use AWS Amplify to bring the mobile application and test it on all of the devices. for the database, they are using DynamoDB as the database, and also for cache purposes, they are using the Redis cache.
Important features in Tinder

- Login and oath — A Tinder login requires you to enter your mobile phone number. You can also link your account to your Apple ID, Google, or Facebook account to log in quickly.
- Discovery and swipe — You can see users' profiles and it suggests your user profile based on the preferences. Then you can do a left or right swipe to any particular given user. If you swipe right that means you like that person and if you swipe left you don’t like that person. Tinder will only let users know that you’re interested when the feeling is mutual.
- Match Feature — If both parties like each other and the application itself shows it as a match then you can start a chat also. Two members must both use the Swipe Right to Like each other to make a match.
What happens when Tinder says you missed a match?
When they tell you that you missed a match it means you used the Swipe Left feature on someone who Liked you.
Discovery Algorithms that Tinder is using
You will learn a high-level idea of these features.
- Active usage —Tinder values active usage of the application as it aims to foster meaningful relationships. If one party is inactive for an extended period, it does not align with the objectives of the platform. For instance, if a match occurs and the parties start texting, a lack of response from the opposite person is considered poor activity. Therefore, being active on the app increases the likelihood of being recommended to other users.
- Tinder collects a lot of information about you —Tinder values active usage of the application as it aims to foster meaningful relationships. If one party is inactive for an extended period, it does not align with the objectives of the platform. For instance, if a match occurs and the parties start texting, a lack of response from one person is considered a poor activity. Therefore, being active on the app increases the likelihood of being recommended to other users.
- Grouping user bases — Tinder assigns a score to each user based on their activity and behavior on the app. This score is then used to group users into buckets, which can help increase the chances of matching with someone who has similar interests and preferences. For example, users in bucket 1 may be more likely to match with other users in bucket 1–3, who share similar tastes and interests.
- Your pickiness/bad actors — you will be not shown in the discovery process if you are doing too many of the right swipes for all the profiles that were shown to you. This is also a bad thing and Tinder is going to penalize you by not showing you in a lot of recommendations. and also if you are not doing a lot of right swipes, Tinder not showing you a lot of recommendations.
- Do you reply? — if a match happens between you and another person you can start a chat and you can continue it for a long time. In such a scenario Tinder will recommend your profile to others also. If a match happens and you are not going to talk with anyone, then Tinder will not recommend your profile to anyone.
- Progressive taxation — if you are a person who gets more matches because you might be super attractive then Tinder will normalize that behavior and not show your profile to many users because the discovery process should be fair enough to all of the users. This is all about equality.
Discovery Engine Design
The discovery process engine ought to suggest users that align with your preferences.
Low Latency —For a seamless experience, the application should have a low latency that enables it to load quickly upon opening.
Not Real Time – It’s acceptable to delay displaying a new user to others in the system.
Fast profile search — there should be fast use of the profile search
Distributed System —To share the data, because we have tons of profiles, we can just keep it in one system.
Filter Capabilities — There should be a facility to filter users by your preferences.
HTTP/Web Socket — There should be an HTTP interface or web socket together data and send it back to the application.
Structured Data —The data should be structured like either XML or JSON.
Elastic Search Mechanism(ELS)
Tinder uses an elastic search mechanism(ELS). Elastic search is a search system as the discovery process engine. ELS is the indexing system, that stores the user documents we use to search and provide recommendations. ES is open source, and the different code versions can be found on GitHub. There are many ways to query Elasticsearch. One of the simplest ways is to store scripts, or search algorithms, in Elasticsearch, and then send queries that reference the script. That way, when the query is interpreted by Elasticsearch, it knows what algorithm to use to search and return results.

Searches in Elasticsearch happen roughly in two steps: filter and sort. In the filter step, all the documents that don’t match the filter criteria are excluded from the results. In the sorting step, all the documents that fit the filter criteria are assigned a relevance factor, ordered from highest to lowest, and put in the response to the caller.
In Elasticsearch, plugins are a way to enhance ElasticSearch's basic functionality. There are many different types of plugins, they allow you to add custom types, or expose new endpoints to the Elasticsearch API.
The type of plugin that interested us most was the script engine or script plugin. This type of plugin allows us to customize the way the relevance assignment is done for the documents.
Data Clustered in Tinder
As a user from Sri Lanka, it would be helpful to receive recommendations primarily from Sri Lanka. The distance settings in the discovery process allow me to specify a radius of 50 kilometers from my current location to search for matches within that area. This helps to cluster the data for a specific location, making it easier to find relevant recommendations.
How to share data to make elastic search queries faster? How do we identify which location to share our data? Storing data is country-specific or geolocation-specific?
The diagram illustrates a method to distribute data into various clusters or geographical regions. The world map is divided into smaller sections, with each box containing a server. Any requests from a particular box will be directed to the server in that box.
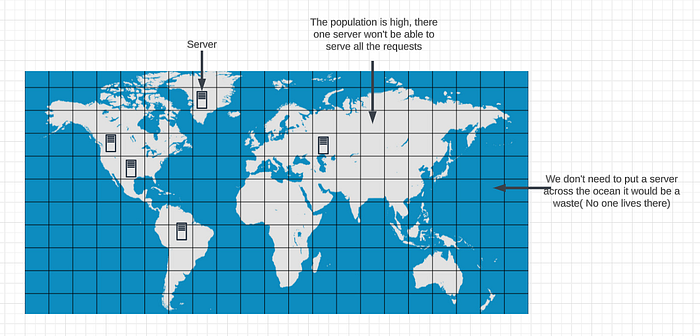
To efficiently distribute the server load, we must divide the world map based on criteria or score. Adding multiple servers might be necessary in certain areas with high traffic, but not in the picture given. How we can handle the distribution of load across our servers?
Tinder determines the size of its boxes in various regions based on the unique user count, active user count, and query count. These factors help the app to gauge the density of users and the system’s performance.
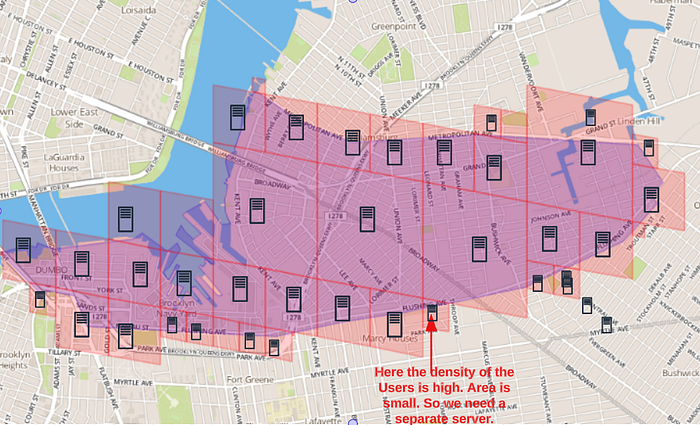
We have to find a balanced score to get the optimal size of the box/cell. Tinder is using the S2 Geometry library to get the geographic data. you just need to give the latitude, longitude, and radius then you can get all the cells/ boxes according to the parameters. The S2 library uses RegionCoverer which allows arbitrary regions to be approximated as unions of cells (CellUnion). This is useful for implementing various sorts of search and precomputation operations. This will let you specify the minimum/maximum cell level and the maximum number of cells used for covering the 2D region.

Tinder group all of the user data belongs to one cell to one server(Elastic clusters or Geoshards).
Cell NO 1 ---> Server 1
Cell NO 2 ---> Server 2
Cell NO 3 ---> Server 3
Cell NO 4 ---> Server 4
Cell NO 5 ---> Server 5
Cell NO 6 ---> Server 6If the resident of cell number 1 sets their desired distance to 100 kilometers, Tinder will only display users within that radius using the S2 Library. Assuming there are six cell numbers within that range, six separate queries will be sent to the servers (servers 1–6). The recommended users will then be displayed based on this data. If a user requests a recommendation, six different queries are sent out to all the cells. These queries are fired into all six servers, which gather approximately 100 recommendations. This is how the recommendation system works based on Geosharding.
Discovery Engine System Design
When a user installs the mobile app for the first time and logs in using Facebook or another platform, they need to create a new user which is done from a server. Once the user is created, the user document is sent to Elasticsearch Feeder services, and then it is processed. A copy of the user document is stored in the database as a persistence storage and also sent to Elasticsearch for faster search and recommendations to others.
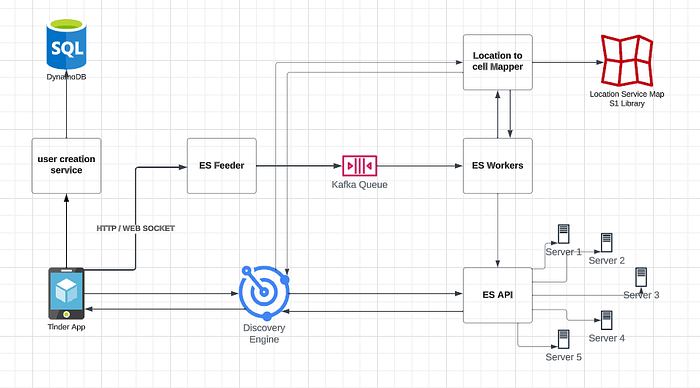
To achieve this, we have a user creation service that adds the user to the database and sends a copy of the document to Elasticsearch. They use an HTTP WebSocket connection to consume the user document and send it to Kafka for asynchronous indexing of the data(Here we can use any Queuing mechanism).
Once the user document is inside the queue, the Elasticsearch workers pick up that message and request the Location mapper service. The location server uses the S2 Library and is aware of the cells. It returns what shard this information will write into. ES Worker then tells into ES and info gets written to that particular shard using ES API.
User information is now saved in Elastic search and he is now ready to do left/right swipe. He then makes a call to the Discovery Engine which in turn calls the location to the cell mapper again with latitude, longitude and it returns multiple server/s to which it makes parallel calls to Server/s and gets a couple of documents/profile and sends this info to the mobile using HTTP/web socket. Now all the profiles are being rendered to the user and he’s ready for left/right swipe.
Countries are located next to each other, but their time zones may vary slightly. So that the traffic also may vary. This is because people tend to swipe right and the left side, resulting in high traffic or load. So we need to share servers efficiently among different time zones considering the traffic.
Match Making Architecture
The design of matchmaking aims to match people with one another. However, several cases need to be considered before implementing it. There are two profiles, A and B, and three possible scenarios can occur:
- Both swipe right at the same time
- One person swipes right and the other doesn’t
- Neither person swipes right
It’s crucial to handle all these cases properly. Whenever one person swipes right, the server checks if the other person has also swiped right.
Every day, millions of matches occur worldwide, and to cater to this demand, we cannot rely on a single service to match everyone. This is why we implemented Geo Sharding. For each cell, we created a matching service, and in case it’s not available, we associated a couple of cells with one matchmaking server. This was necessary because a single server for a country or location would not be able to handle the heavy load of queries. Geo-sharding helps balance out the queries per location, and matches usually happen within the same cell from where the profiles were recommended. We can also map this service to recommend only a few profiles as it’s unlikely for all 100 recommended profiles to be matched. The matchmaking service works by associating cells with matching servers to balance out the traffic and ensure successful matches.
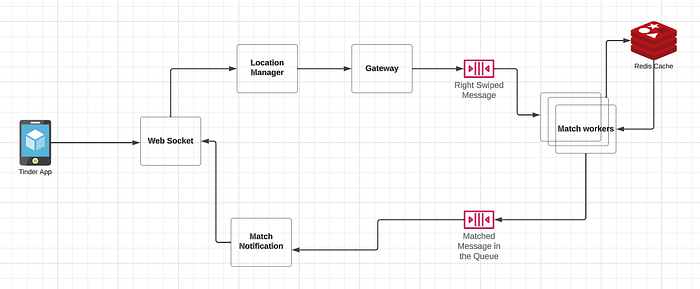
The graph above shows that when a user performs a right swipe, a message is sent to the matchmaking service via WebSocket. The location manager then determines which shared or matchmaking service the message should go to and redirects it to the gateway, which connects to Kafka Queue. Depending on the number of shards, the message is placed in a queue. The location manager service broadcasts this information to one or many matchmaking services(Match workers) based on the servers that belong to the person. To decide the information taken from the user that information includes who is right shipping whom, location, and other metadata. Match Making workers are threads or processes on the parallel threads. Match Making use of stream processing technologies and you can implement these using Spark Streaming and Flink.
Multiple parallel match-making workers can read messages from the Kafka queue.
Match-Making Logic in Match Workers
Whenever A right swipe, an entry is made in Redis as A_B, which is left as it is. Similarly, when B right-swipes A, the same process takes place. The matchmaker checks Redis for a match by finding Key AB and checking for metadata. If a match is found, the message is added to the match Queue. The match notification picks the message and sends it to both A and B through WebSockets, indicating it’s a match. If for some reason, A has never right-swiped B then what will happen? Then just a record “B_A” will enter into Redis and that’s it. when A right swipes back B then before adding the key it will check for the key.
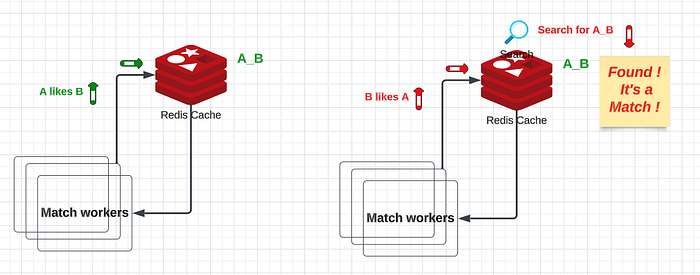
Problem: Assume you are in Region 1 and another person lives in the same region. And he/she likes you(swipes right). But then you moved to another region Region 2. In that scenario, that person might not show to you as a recommendation. To solve this you can maintain a global centralized Redis/NoSQL DB then all the entries will be available everywhere.
User Super Like Reactivation
Let’s focus on reactivation for both,
- User reactivation
- Super likes reactivation
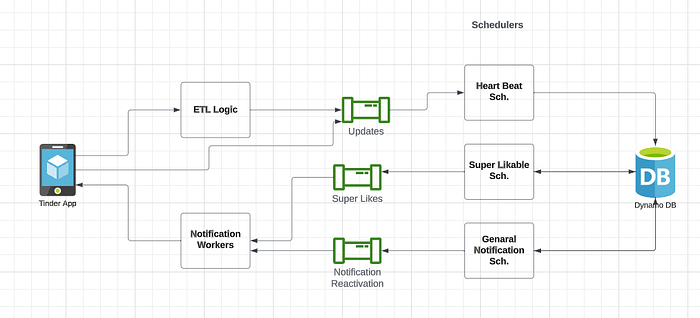
To achieve this, we need a scheduling system that can automatically provide super likes for users. For user reactivation, there are multiple cases to consider. For instance, when a new user logs in for the first time, they need to upload pictures and update their status. If users fail to complete these actions, we should remind them to finish their profile updation. Additionally, we also need to reactivate users who have stopped using Tinder. To achieve this, we can send notifications to remind the user to start using Tinder again. Building a scheduling service at scale can be a little difficult, and we need to do a lot of asynchronous processing. We require many workers to handle this system, and we have two different schedules: one for super likable and the other for general notifications. All user actions within the Tinder application will be converted into logs and sent to ETL(ETL stands for extract, transform logic).
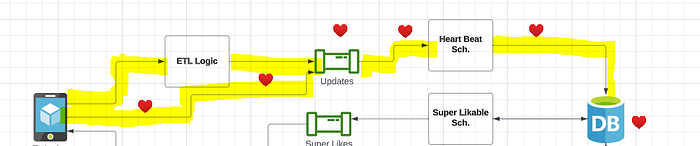
The ET logic is used for real-time stream processing, batch processing, or analytics. It is important to keep sending updates to the queue regularly. For instance, it is crucial to know the last login or usage time of a user to keep track of the last time they visited Tinder. To achieve this, the heartbeat(❤️ ) is saved every 10 minutes, and this information is consumed by the workers(a scheduler) from the queue. The workers will then update the information to the DB against the particular user and the last updated time. This is how we determine the last time the user visited Tinder.
Dynamo DB is the preferred database for Tinder(Dynamo DB provides TTL features). Once a heartbeat is sent from the phone to the queue and consumed, the TTL(Time to Live) is set to 24 hours. The scheduler will know which records have timed out in the Dynamo DB and send notifications to the user accordingly through the Notification Scheduler. When the message is dropped into notification queue A, the notification workers will pick it up. If an active connection is already present, it will use the existing connection to notify the user. If the active connection is not available it uses a Google notification to send the notification to the user.
User Login and User Profile Modules
How to store User Profile Information?
To effectively implement user login and profile modules for data, we can make use of the user profile information already stored in Elastic Search, specifically Geo shards. Additionally, we can consider having another API exposed from Elasticsearch to provide specific user profile information. To optimize performance, we can add another layer of cache in front of Elastic Search. However, it is also important to have all user profile information stored in the database for reliable storage purposes. To link all order information together, we could use RDBMS, which works well for a database with only a couple of million rows. If we choose to use RDBMS, we should be sharding by geography for better queries. If RDBMS is not preferred, we can go with NoSQL, which is always a good option as it is a distributed database that automatically scales itself. With a document-based database, we can guarantee that all payments and orders can be stored in the database as documents.
How to enable user login?
A user can log in using FB oAuth by registering our application in FB API. or the user can use phone number verification using an OTP code. We can get lots of information like places users have visited, likes, dislikes, close friends, etc, as Tinder wants to build a relationship app, we need to have a legitimate profile and decide should we need to show this profile to others or not. We don’t need to implement sessions here. Since we are trying to write an app in native Android or iOS, we don’t need to have sessions all we need is to maintain an authentication token.
User and Content Moderation
To maintain the quality of the system, it is important to verify and validate any updates or changes made. As a user, he has complete control over his profile, which means he can post anything on his status or upload any pictures. However, it is essential to take care of the content and remove any bad or inappropriate material to maintain the reputation of the system. Moderation is necessary, and we need to find a way to do it effectively. One strategy is to record every action a user performs as an event and store it in a persistent storage like HDFS. MapReduce, Kafka, Spark, or batch processing frameworks can be used to extract information from these events. For instance, machine learning processing can be used to analyze recently updated pictures to identify interesting factors.
In today’s world, it seems like everyone wants to become famous on social media platforms like Tinder. Similarly, people on dating apps like Tinder want to increase their matches, even if it means using pictures of good-looking celebrities found on the internet. However, such behavior should be criticized as it decreases the reputation of Tinder. Therefore, it’s crucial to detect such events and take necessary action. For instance, if a user uploads a blank picture, it should not be allowed on the system. Additionally, we must monitor the rate at which users swipe right. It’s necessary to ensure that they are genuinely interested in the other person’s profile and not just blindly swiping right to get a match. We need to identify such patterns and implement progressive taxation to curb such behavior.
Monitoring
Let’s discuss the feature of monitoring without actually monitoring. It’s important to understand what’s happening in our system and ensure that all of our systems are performing as intended and meeting SLA compliance. One popular technology for this purpose is the Prometheus and it’s an open-source monitoring tool, which offers a wide range of features such as custom queries and alerting.

It can also act as a database for retrieving data and analyzing logs(Can take logs for a specific range and do analysis). Its main purpose is for monitoring rather than data storage, making it ideal for monitoring application and system performance.
In addition, Events(User events as discussed in the Moderating section) can be forwarded to Kafka messages and read by Prometheus, requiring the use of aggregators to calculate requests per second and latency in different geographic locations and shards. It’s important to continuously calculate performance to ensure optimal system operations.
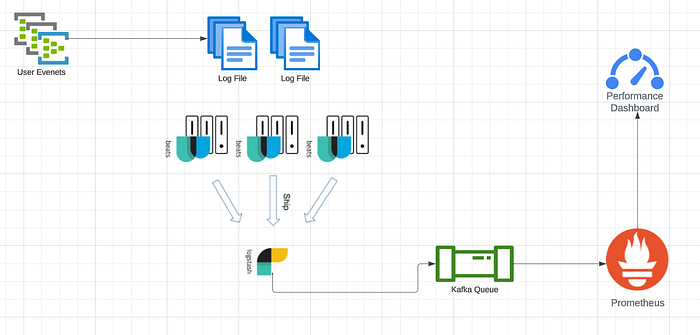
To ensure optimal performance on Tinder, it’s crucial to monitor traffic in specific cells or cities where many users are logging in. We must implement auto-scaling and continuously monitor for any performance issues or increased latency. To accomplish this, we have established various rules such as utilizing an event sink to collect and aggregate data on different topics. By leveraging tools like Filebeat and Logstash, we can easily forward log files and track server performance on the same dashboard. This system allows us to efficiently analyze hundreds of log lines and ensure our users have a seamless experience.
In this article, we have discussed the Tinder features, technical background, geosharding, matches, swipes, content moderation, and monitoring. I hope you get a great idea about the architecture behind this application.
See you in another article. Happy Reading!
Thank You!